︎ Zhenxiao Yang ︎ Zhenxiao Yang ︎
Zhenxiao Yang ︎ Zhenxiao Yang ︎
Zhenxiao Yang ︎ Zhenxiao Yang ︎
Zhenxiao Yang ︎ Zhenxiao Yang
M.Arch Thesis
Design
Site
AI
Social
Furniture
Parametric
Publication
Design Build
Graphic Design
Site

AI

Social


Furniture
Parametric



Publication

Design Build

Graphic Design


01110111 01110100 01100110
Ctrl + C / Ctrl + VThis is a set of AI-driven projects investigating one of AI’s most prominent features, style transfer, in custom applications.
Two avenues of experimentation goals are:
1. Exploring design space that is contextually relevant to the project(Since the images are generated with existing images from a project, further generations may be similar enough that they could be feasible ideas that push the design space for that project. This functions as a more specific means of exploring design space as opposed to experimenting with a more general AI model.)
2. Recreating the representational style from the original dataset(Since the model is built on project specific drawings, an AI model can enable a workflow where no further edits are required after image generation to make these images presentation ready.)
1. Exploring design space that is contextually relevant to the project(Since the images are generated with existing images from a project, further generations may be similar enough that they could be feasible ideas that push the design space for that project. This functions as a more specific means of exploring design space as opposed to experimenting with a more general AI model.)
2. Recreating the representational style from the original dataset(Since the model is built on project specific drawings, an AI model can enable a workflow where no further edits are required after image generation to make these images presentation ready.)
experiment #1
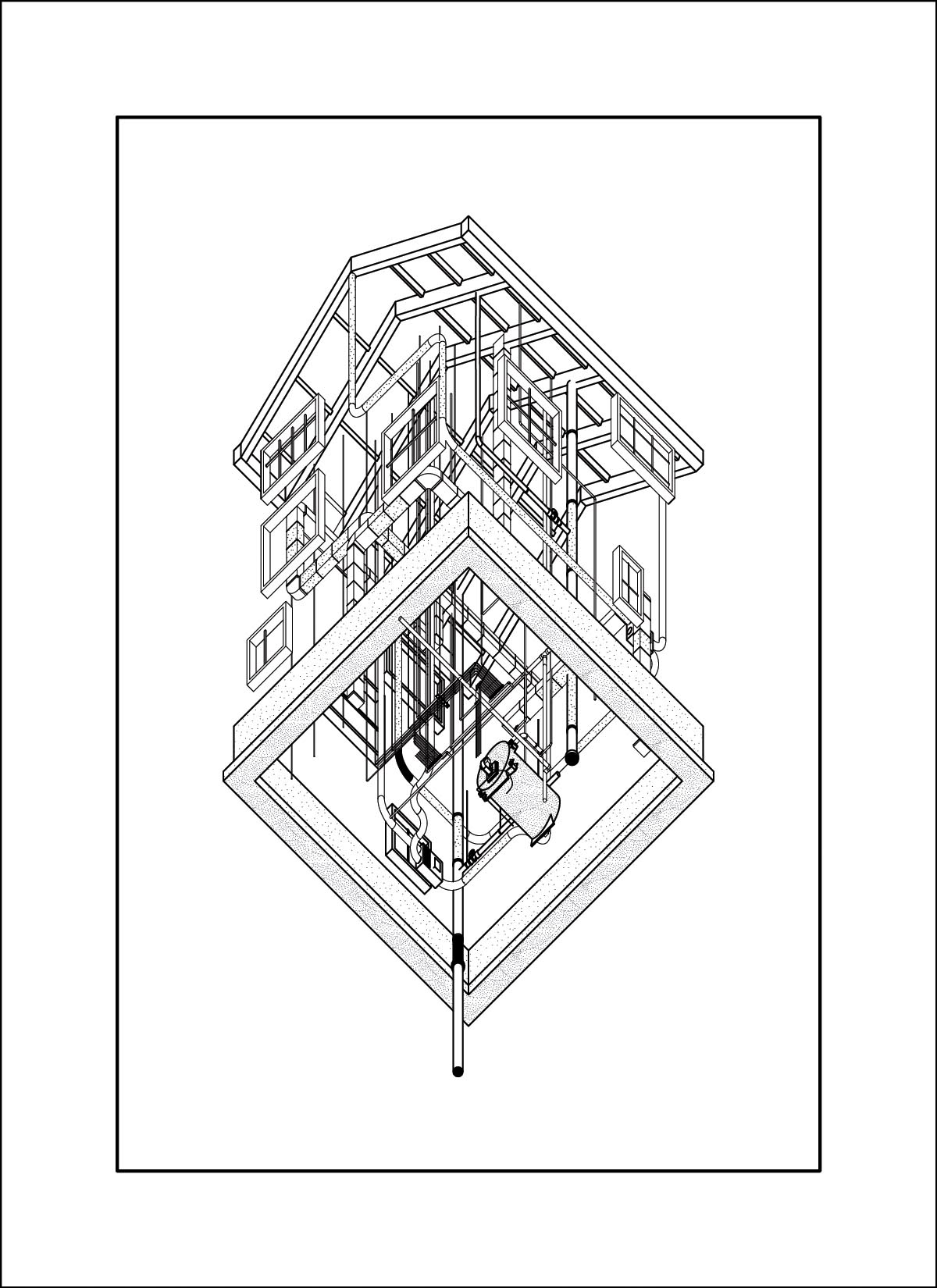
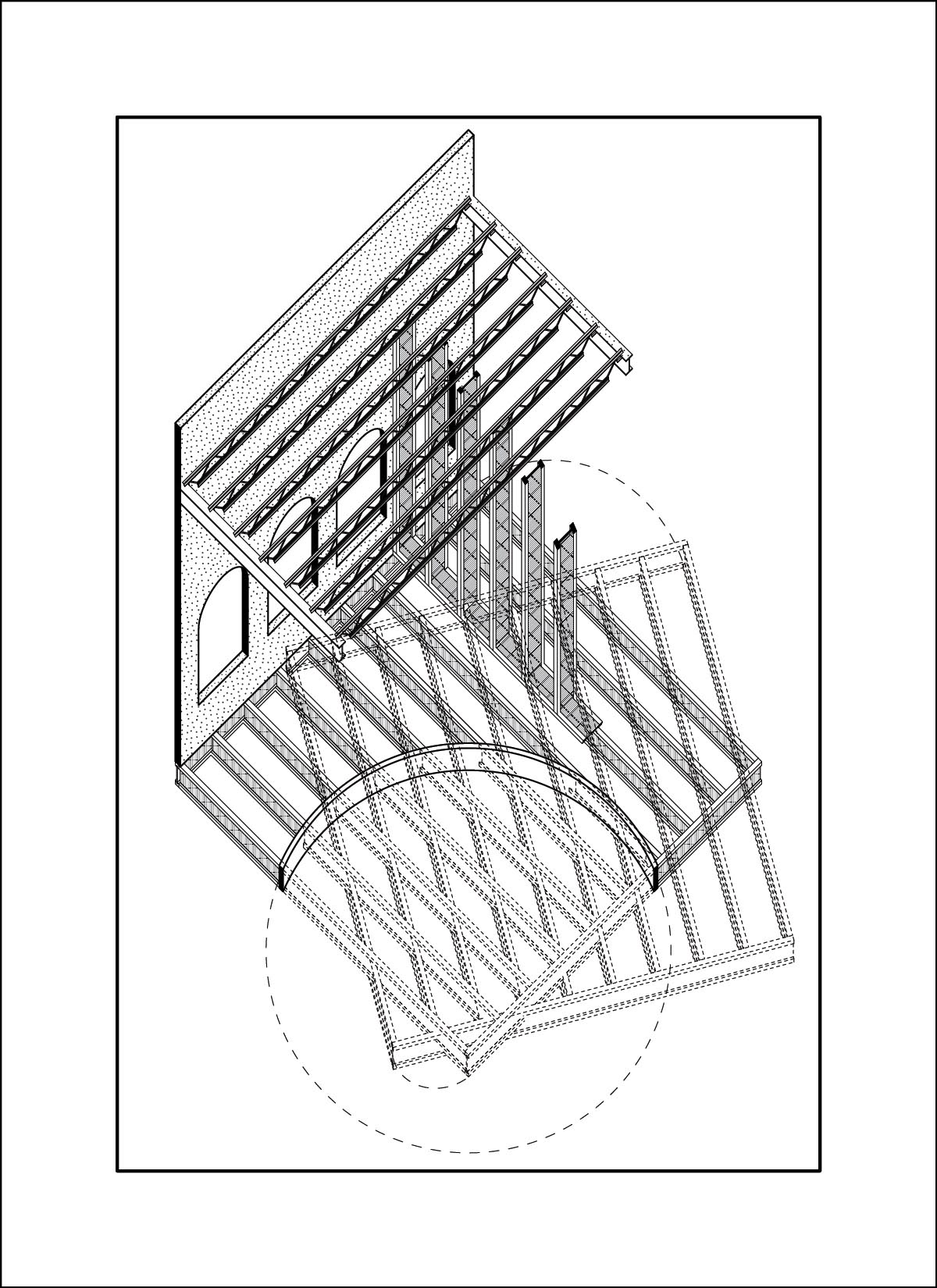
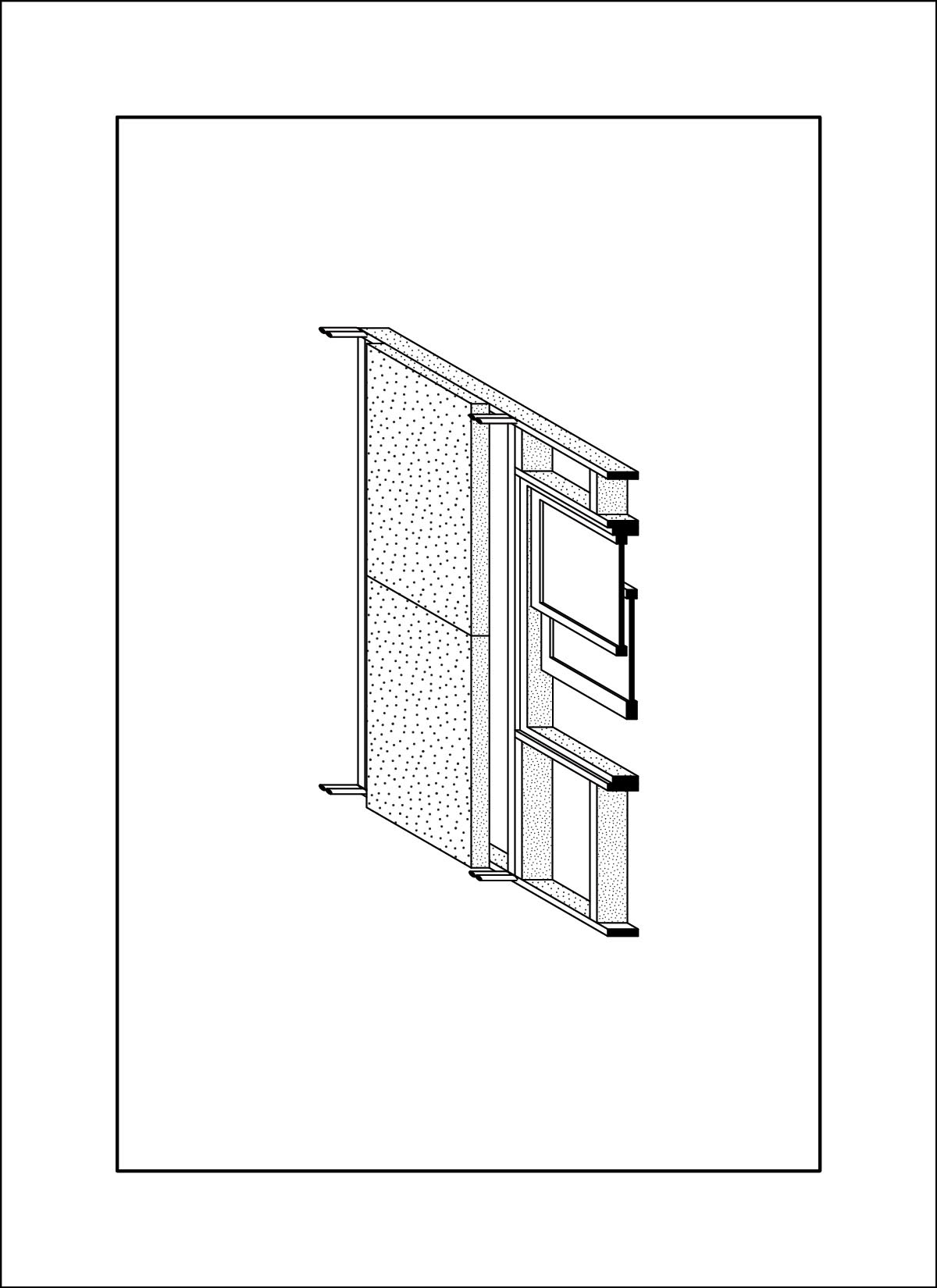
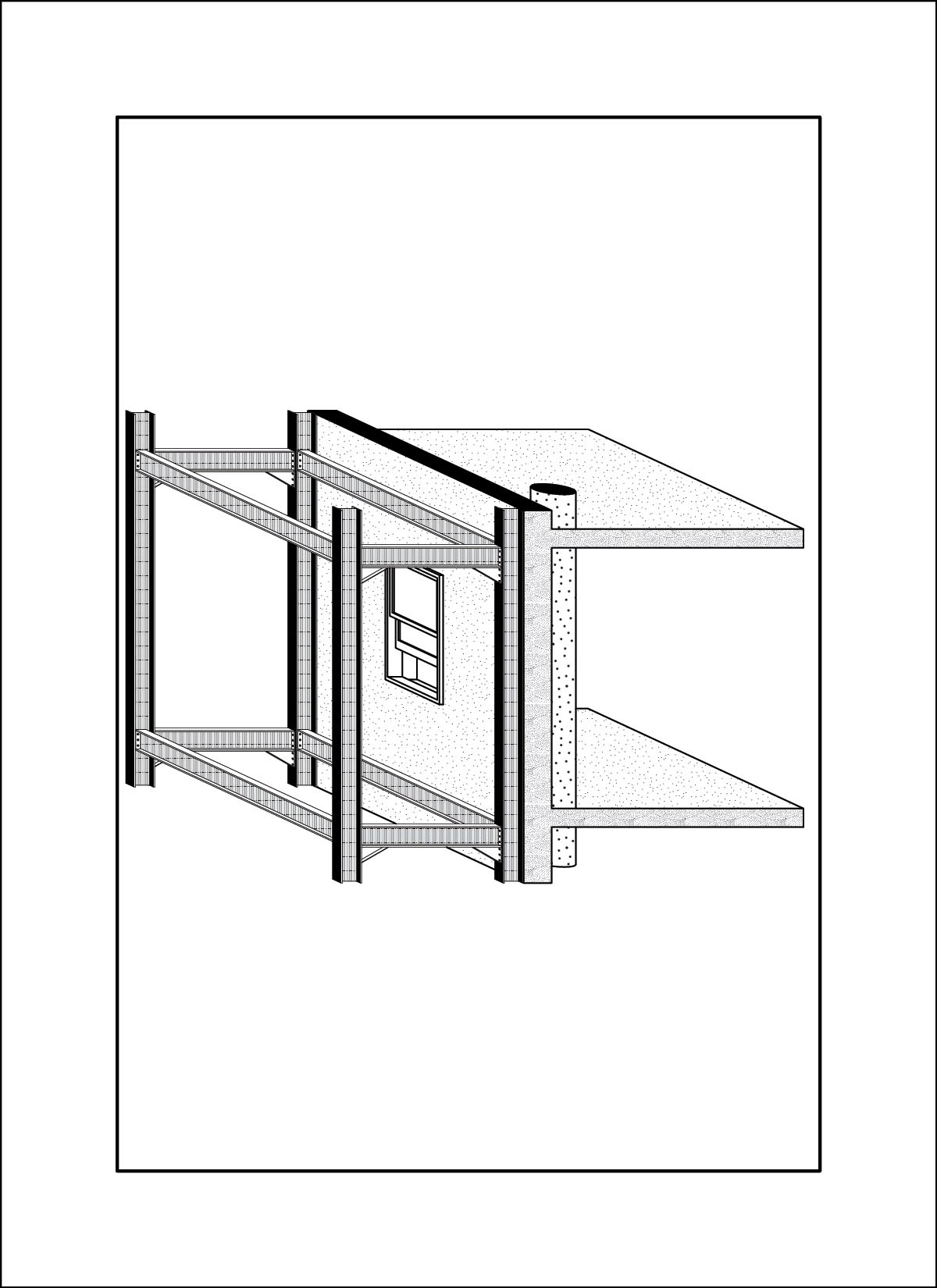
A close friend and colleague, Daniel Wong, was interested in the lifespan of buildings and their components for his thesis work, and in the process had drawn enough images that a clear visual style was established. Using these drawing sets we trained two LORA’s and generated new images.
Try it out yourself here.
dataset - drawings by Daniel Wong








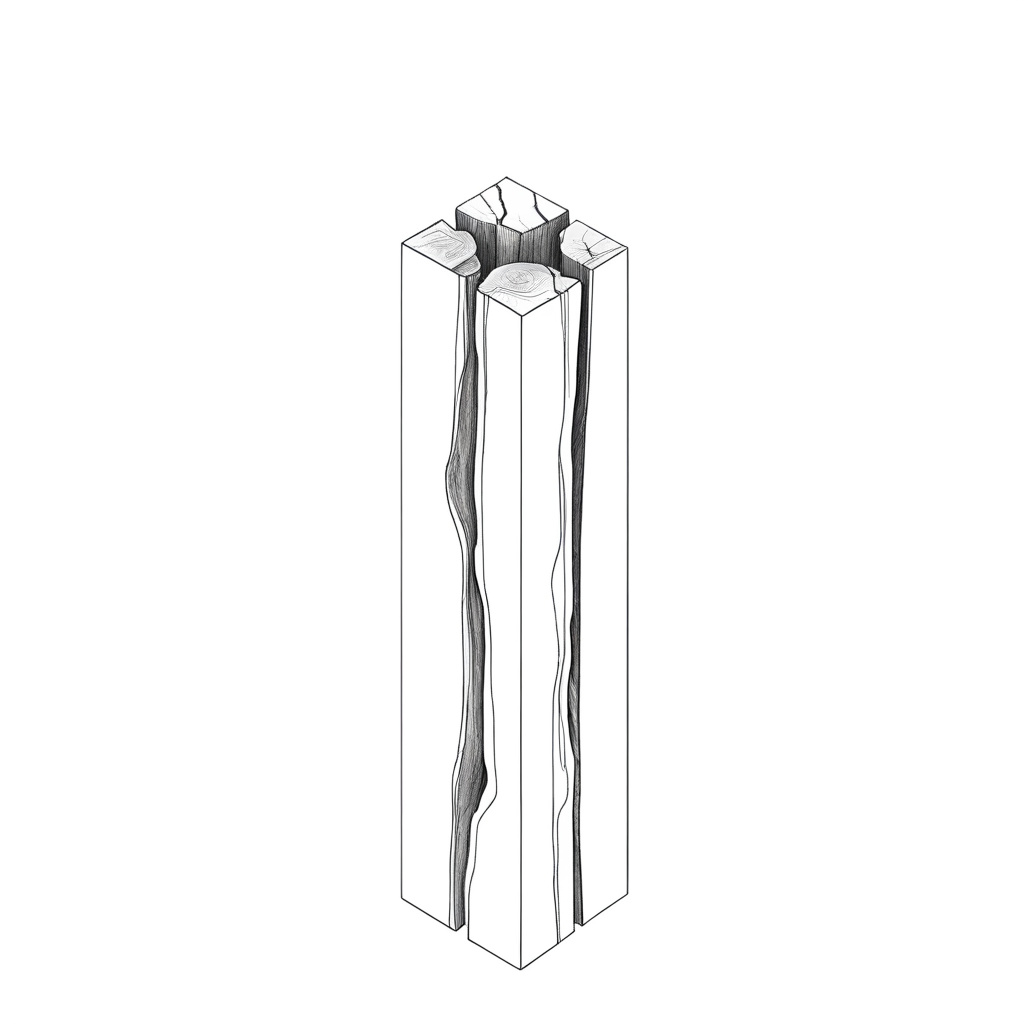
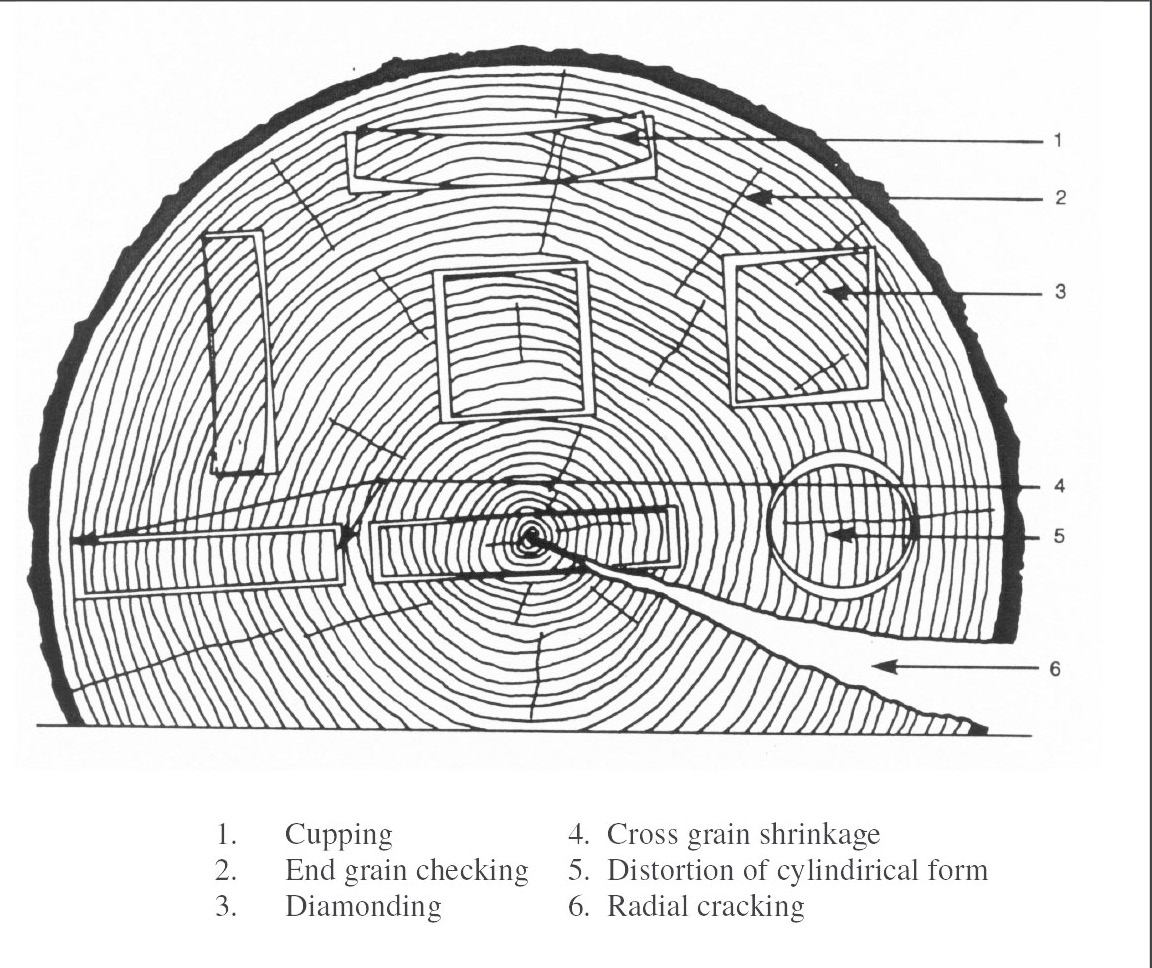
At this time I was also working on my own thesis regarding trees, so a lot of the input images are from my research material. These had very interesting outcomes, as a lot of the outputs are very consistent on composition and color. The model also skews heavily in favor of isometric and 2-point perspective views, which matches the views used in the training data.


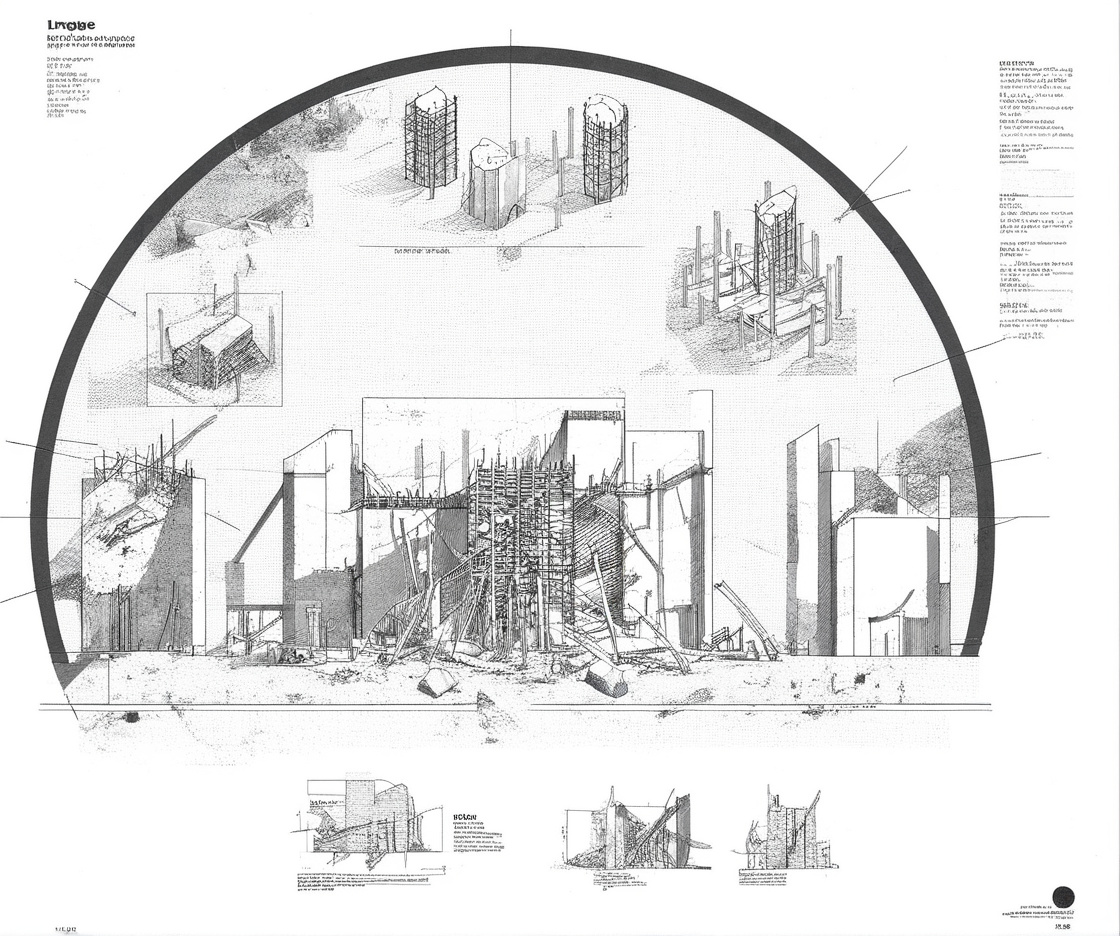




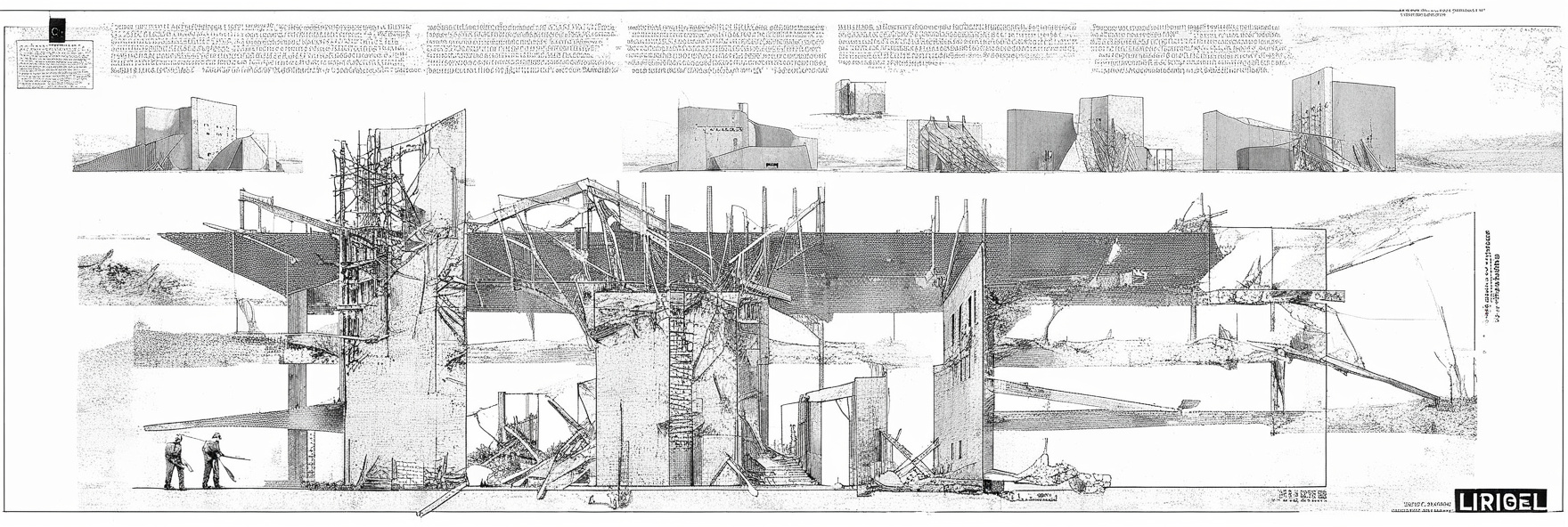
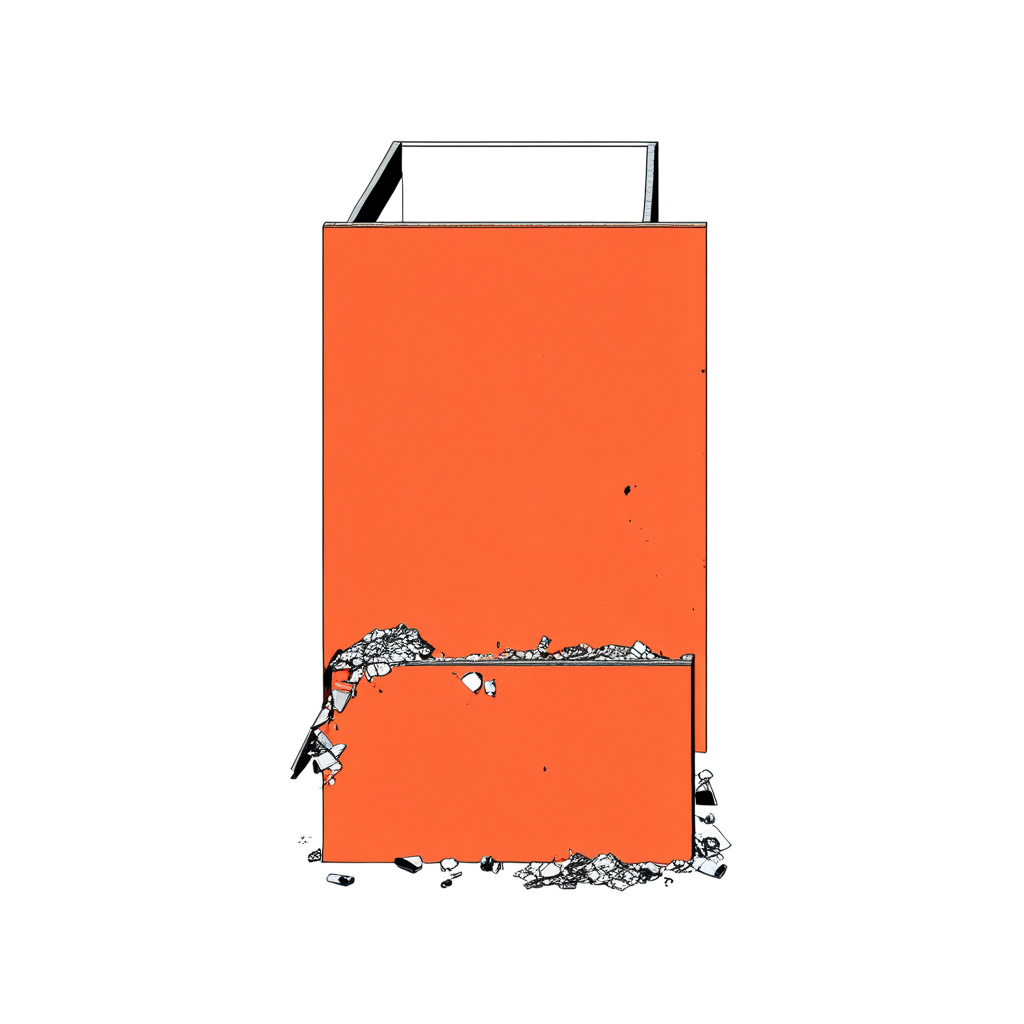
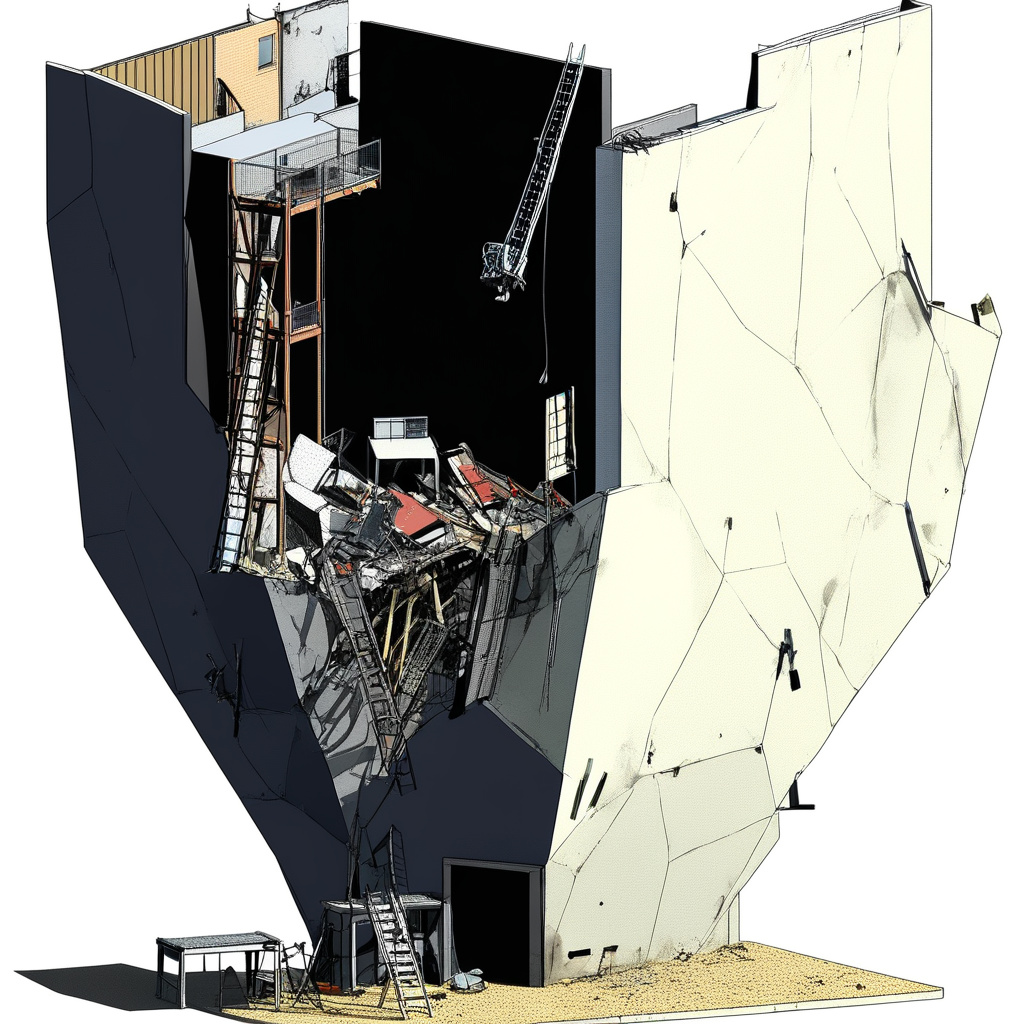
The odd generation is actually this image below, the input is a plate from a set of section/elevations of how ship masts are composited. The input dataset however contains no drawings of that view. I’m guessing that this output is a result of some influence from the main AI model and not from the LORA, or from some of the generic word prompted included like “architecture, decay, rubble, rebuild” etc.
more technical explanation: Ok so a huge misnomer is that people think of “AI” and “AI models” as a singular entity that takes some kind of input and gives some kind of output. AI models are more like a cake that has multiple layers, each layer processes the input image into other forms of information (vectors, words etc.) and at the end outputs another image. The LORA (Low-Ranking Adaptation) here is a layer that heavily influences and guides the output image into a particular style, and are relatively easy to train as compared to the main AI model, which requires a far larger dataset and more computational power. You can also stack LORA’s to really refine your output results, think of them as “data add-ons” that help you generate images your main AI model isn’t well-versed in.
more technical explanation: Ok so a huge misnomer is that people think of “AI” and “AI models” as a singular entity that takes some kind of input and gives some kind of output. AI models are more like a cake that has multiple layers, each layer processes the input image into other forms of information (vectors, words etc.) and at the end outputs another image. The LORA (Low-Ranking Adaptation) here is a layer that heavily influences and guides the output image into a particular style, and are relatively easy to train as compared to the main AI model, which requires a far larger dataset and more computational power. You can also stack LORA’s to really refine your output results, think of them as “data add-ons” that help you generate images your main AI model isn’t well-versed in.

experiment #2
This dataset is twice as large as the previous, and is very consistent in visual style and framing. While the style outputs consistently, I wasn’t able to recreate the frame around images.
Try this model out here
dataset - drawings by Daniel Wong
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
AI outputs
Try this model out here
dataset - drawings by Daniel Wong
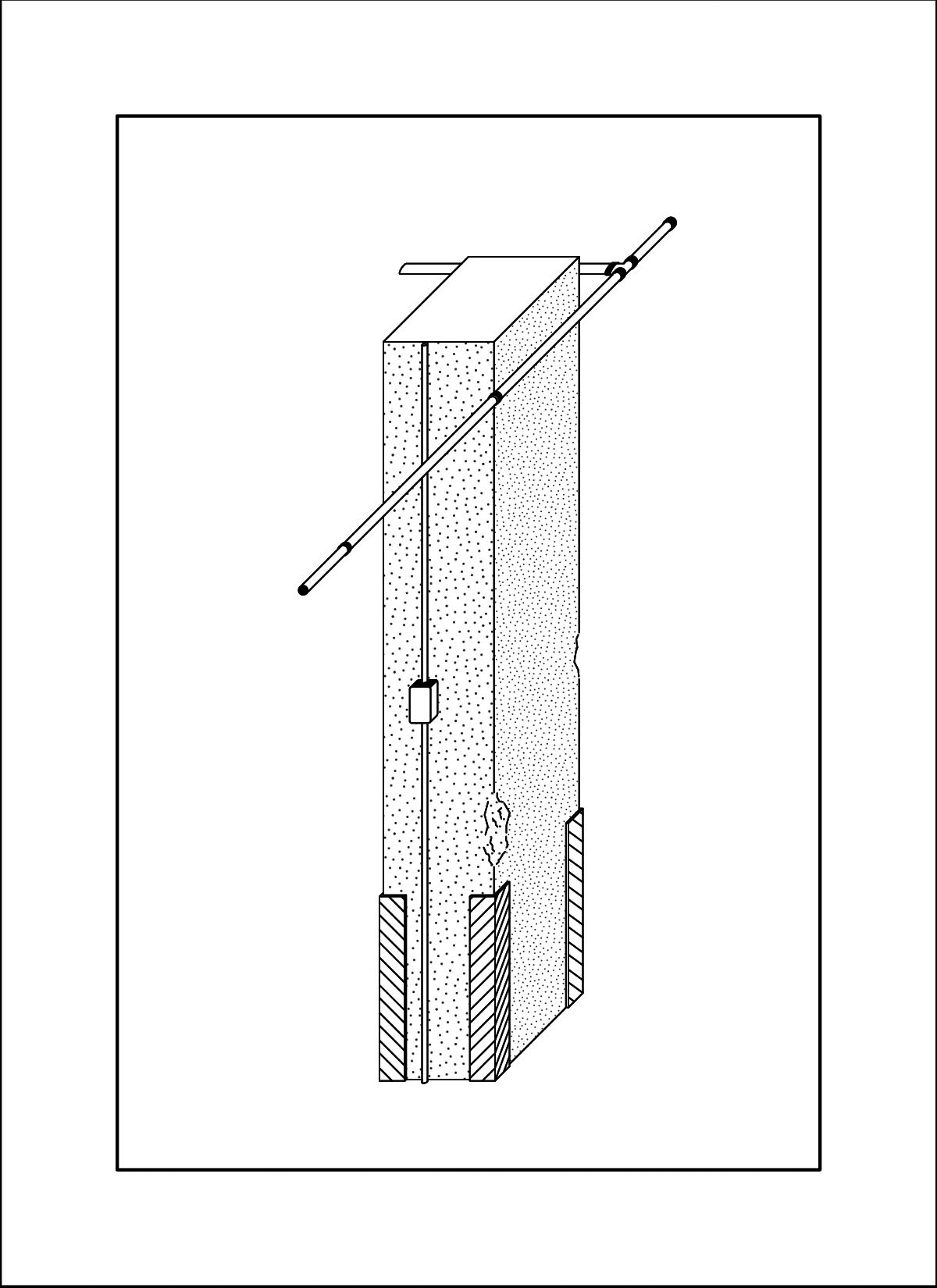

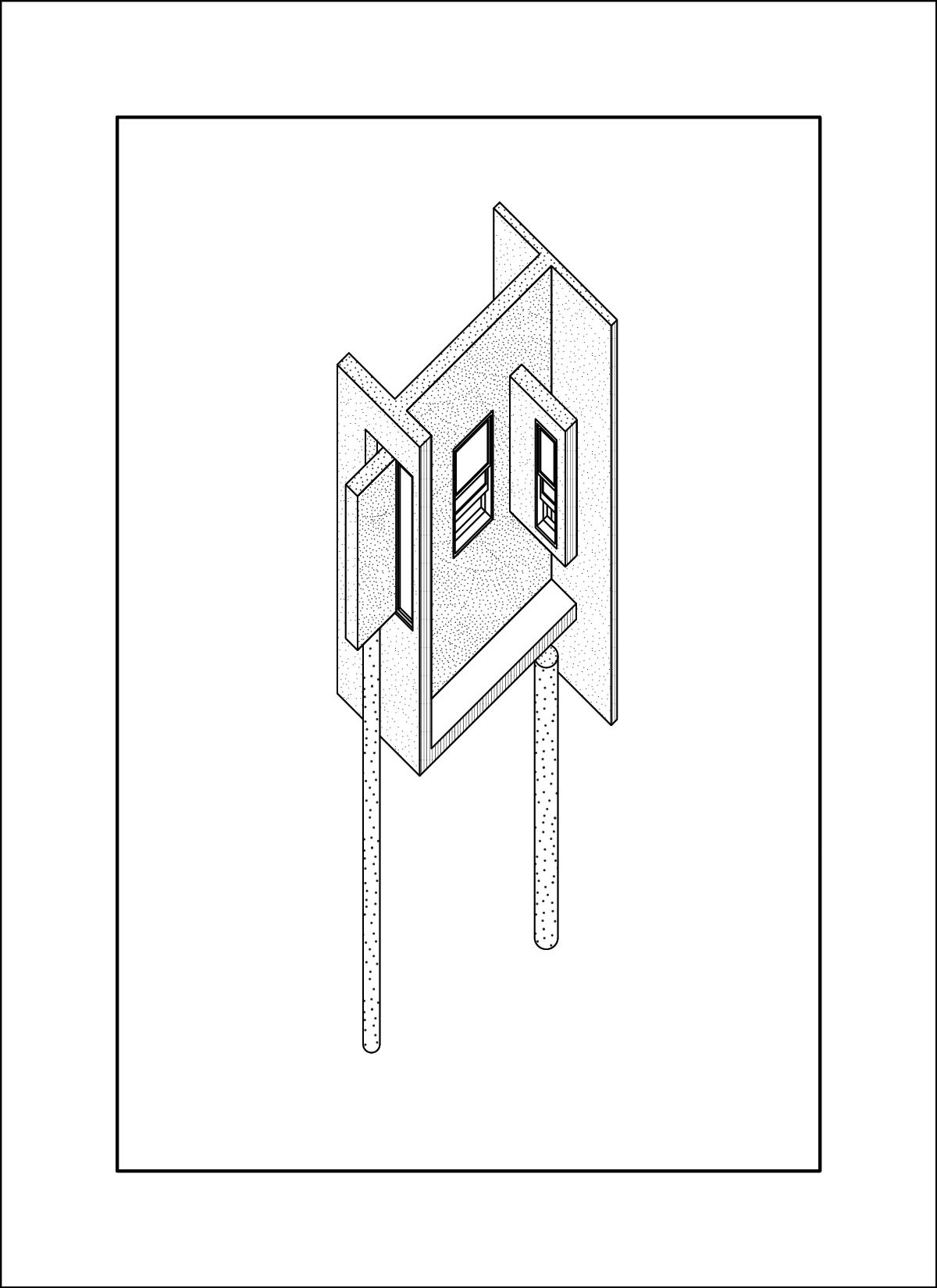
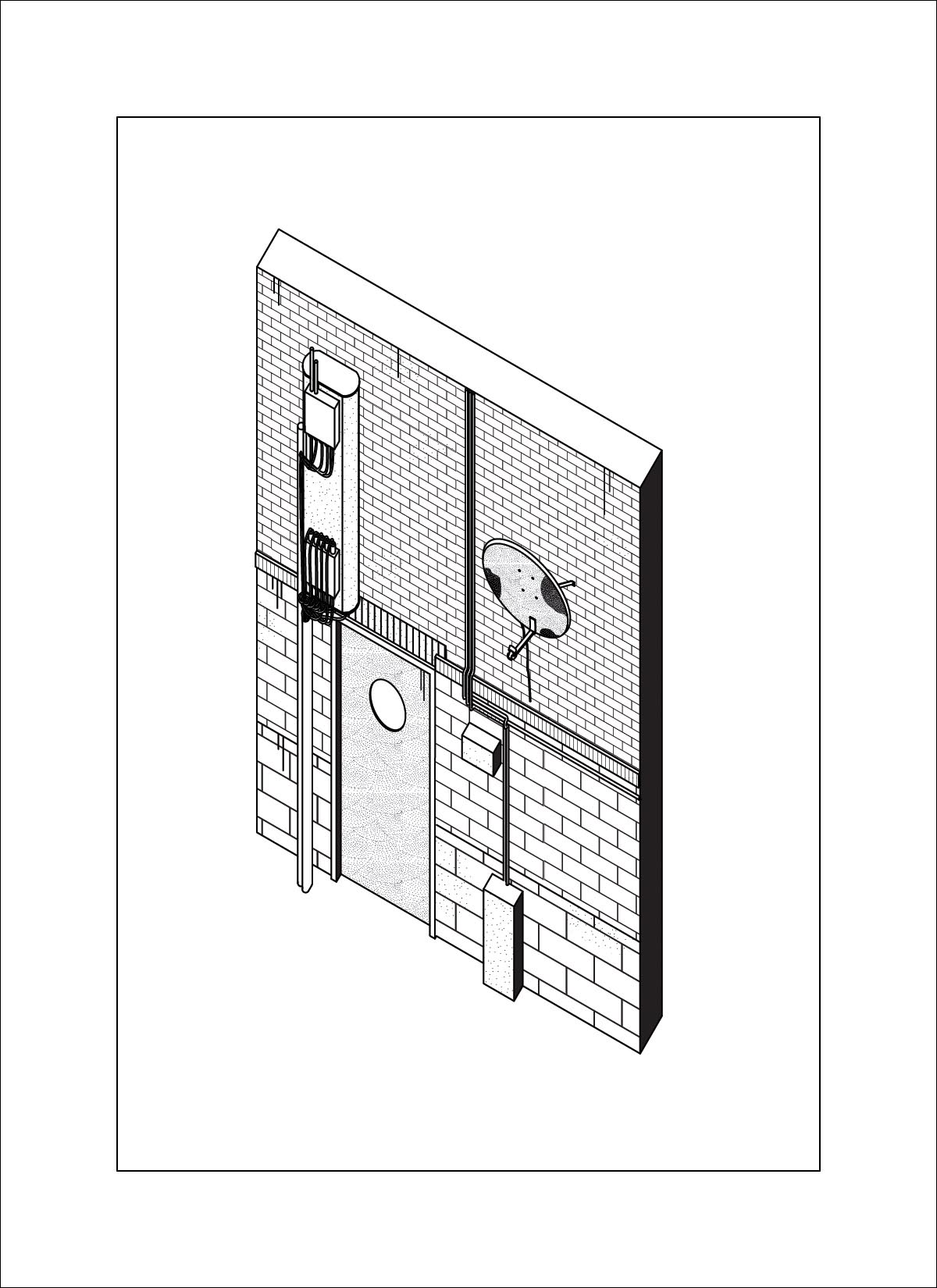

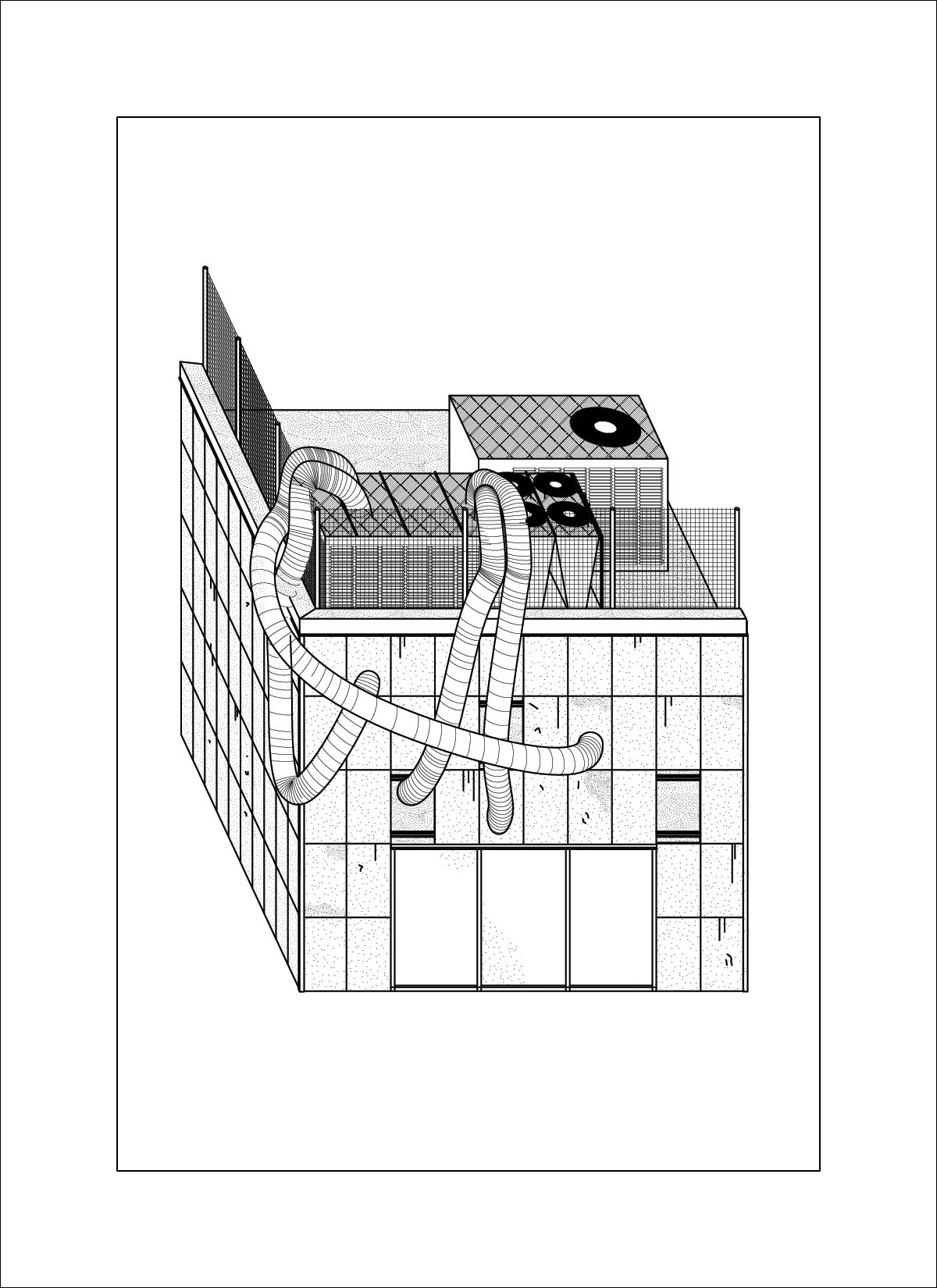
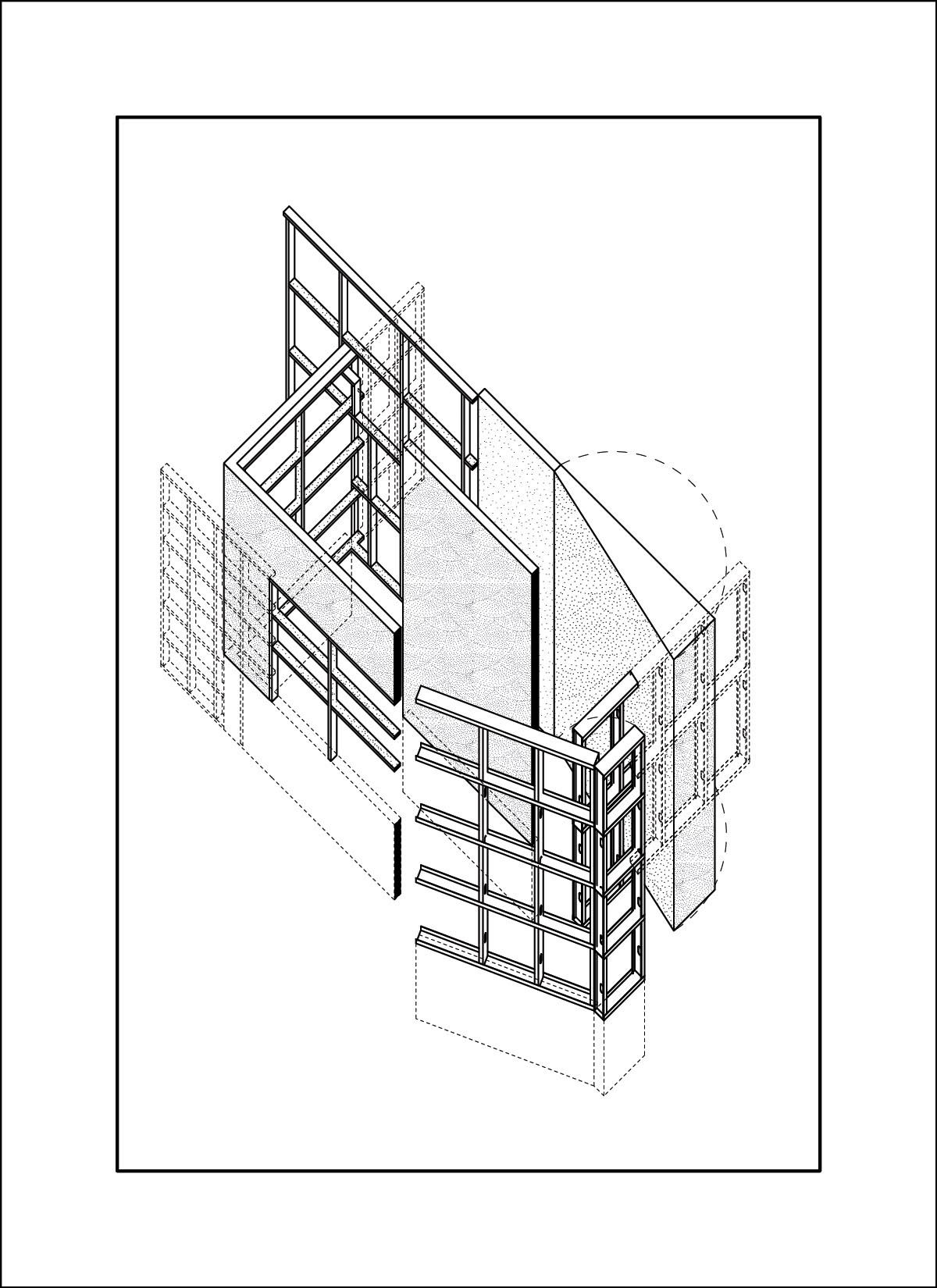
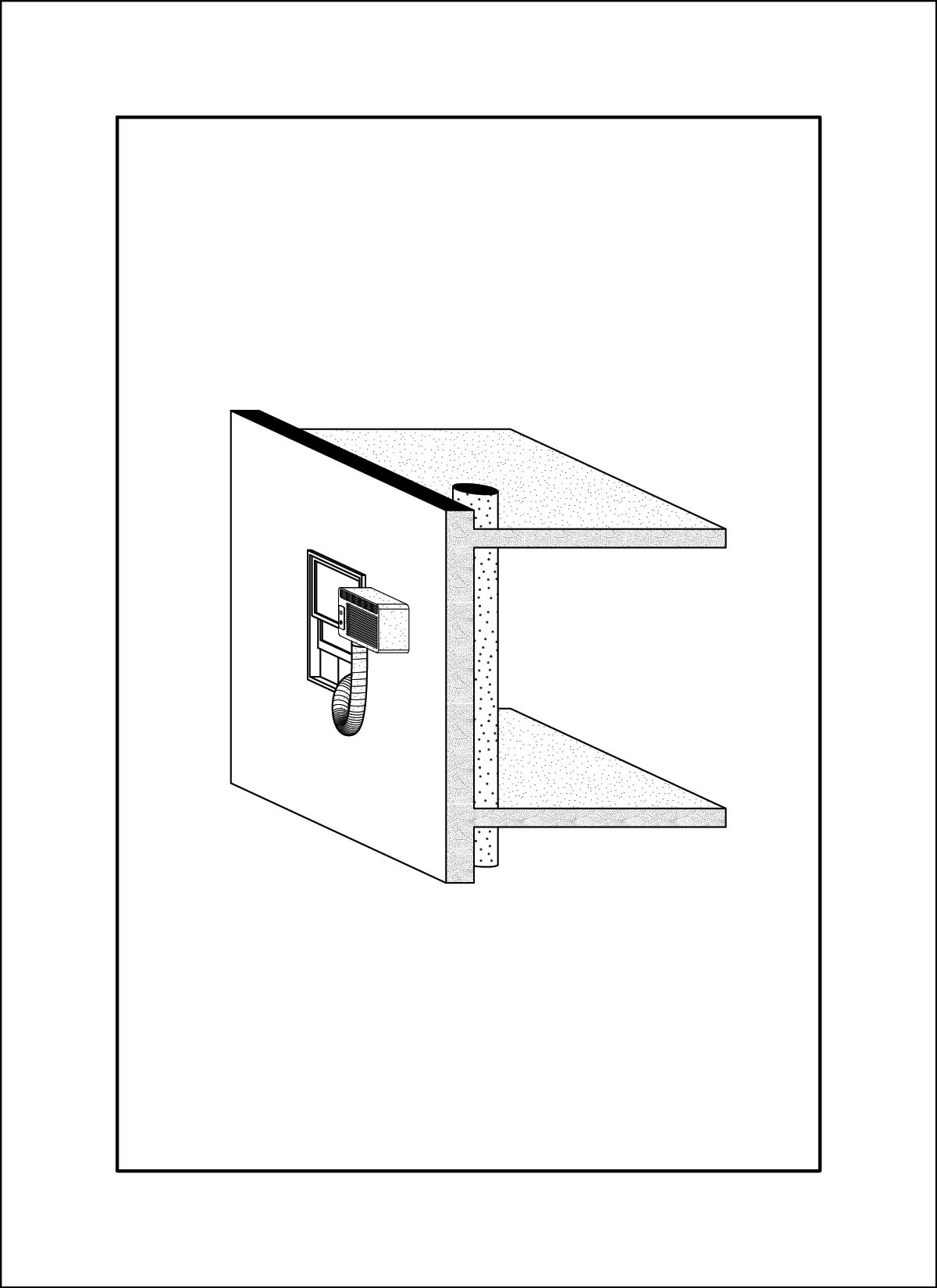

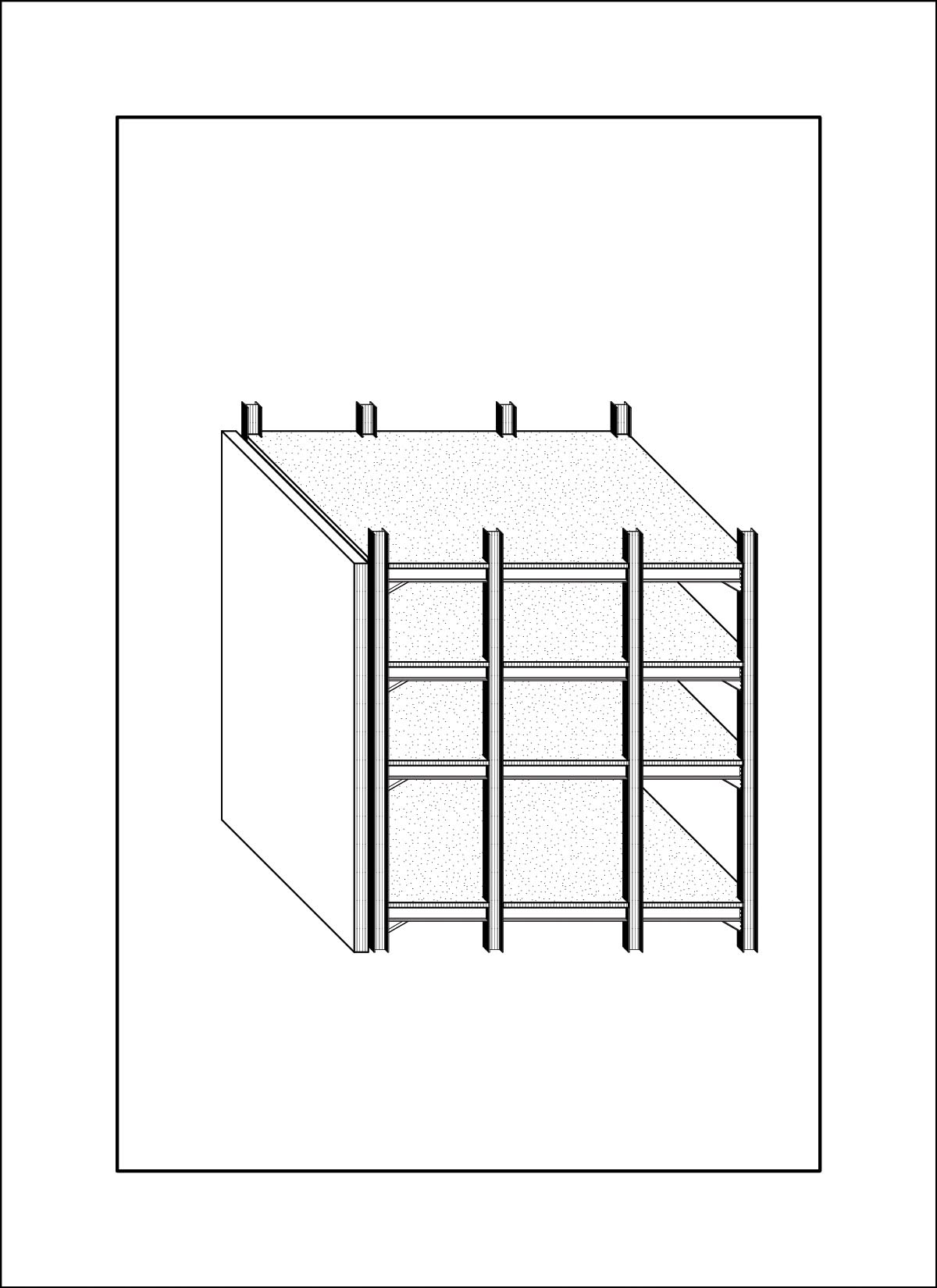
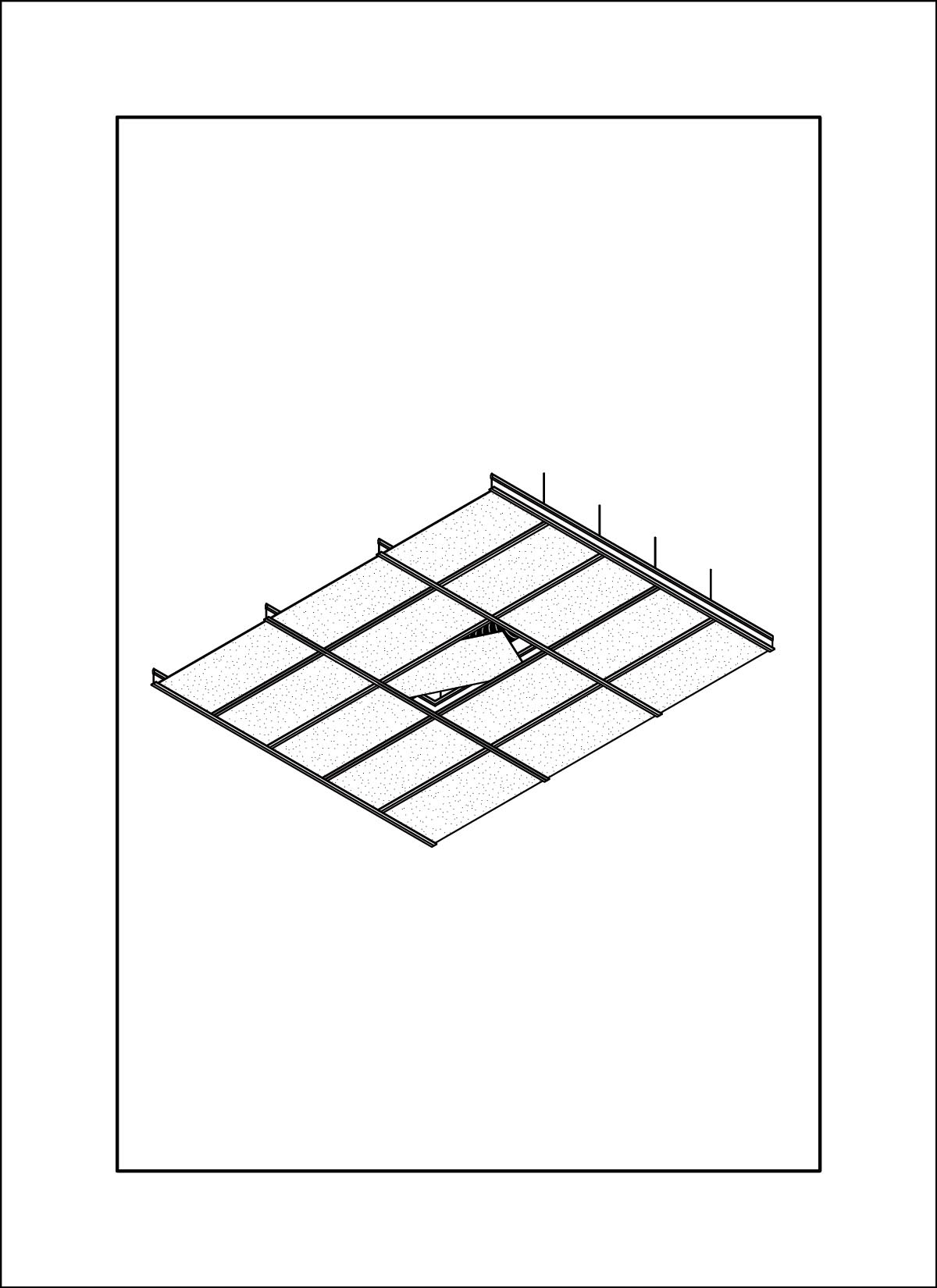

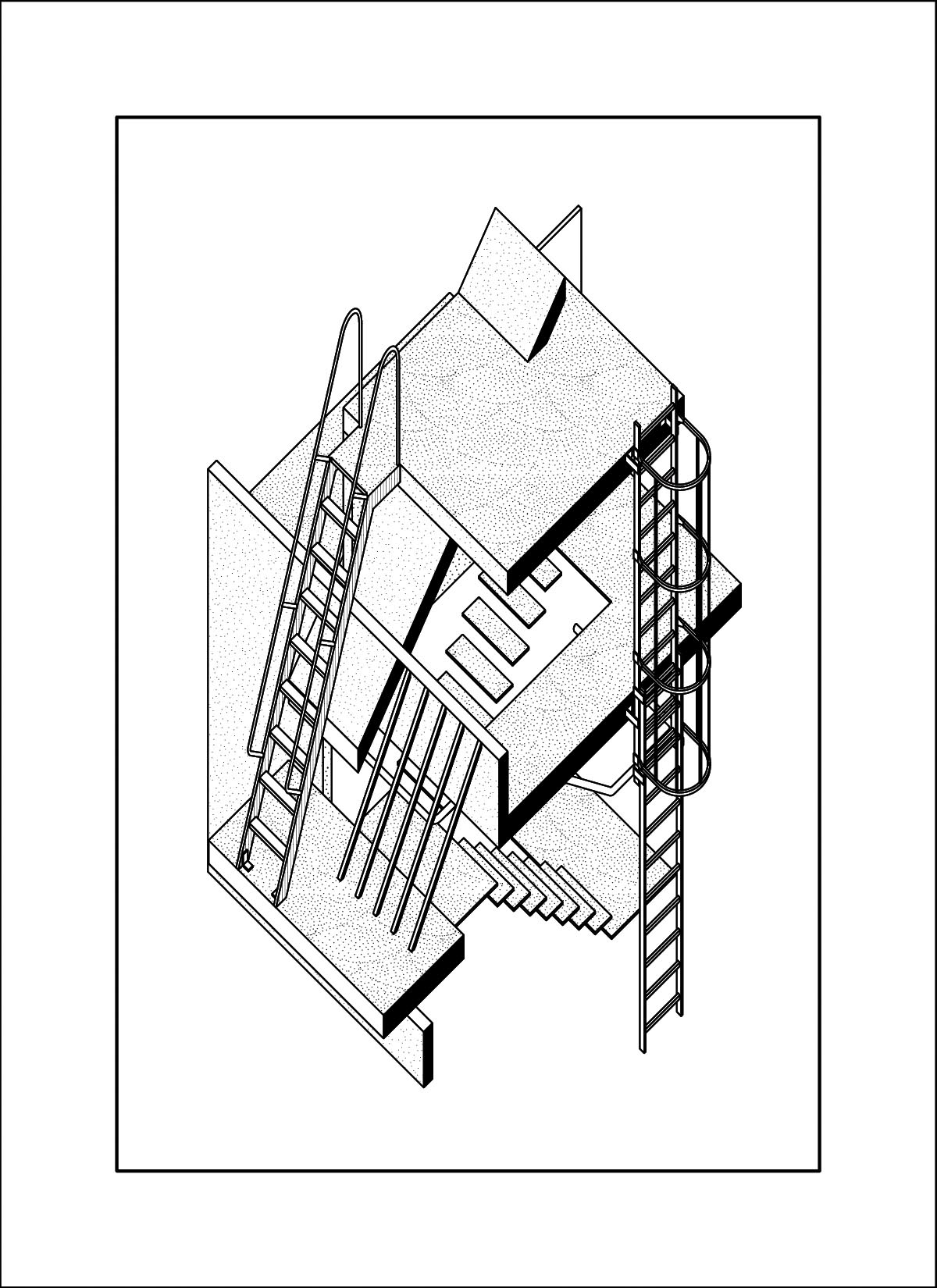
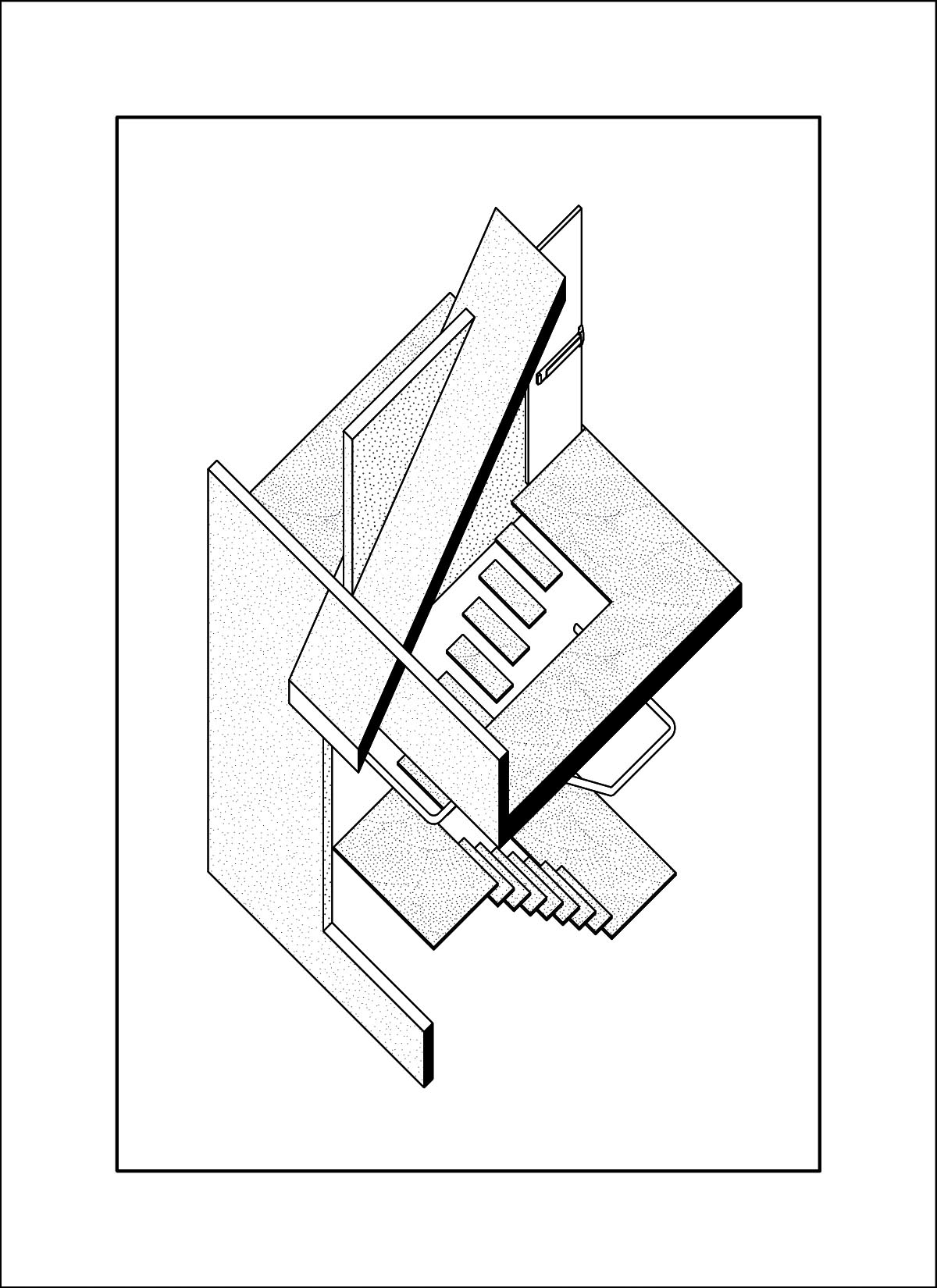
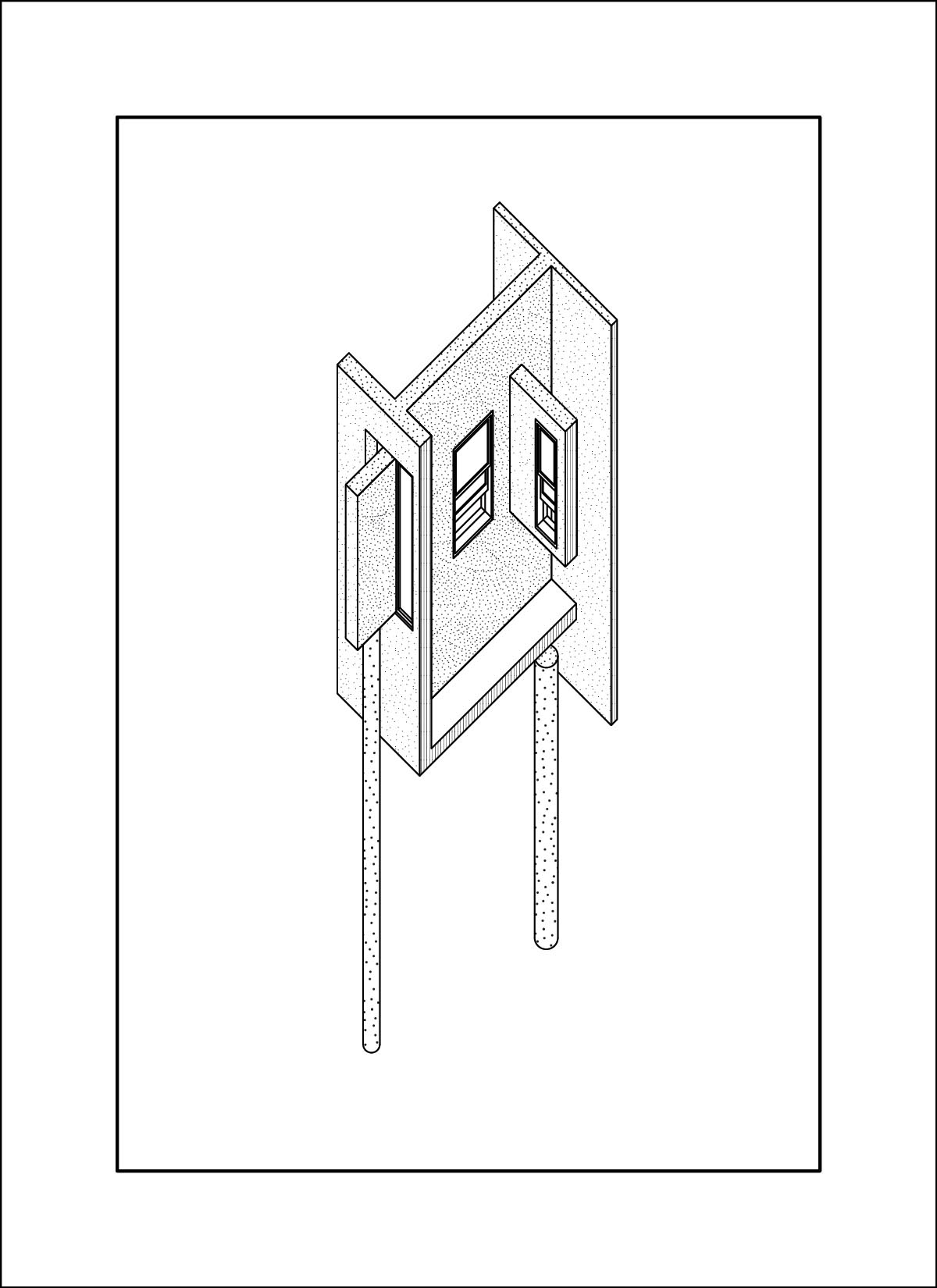
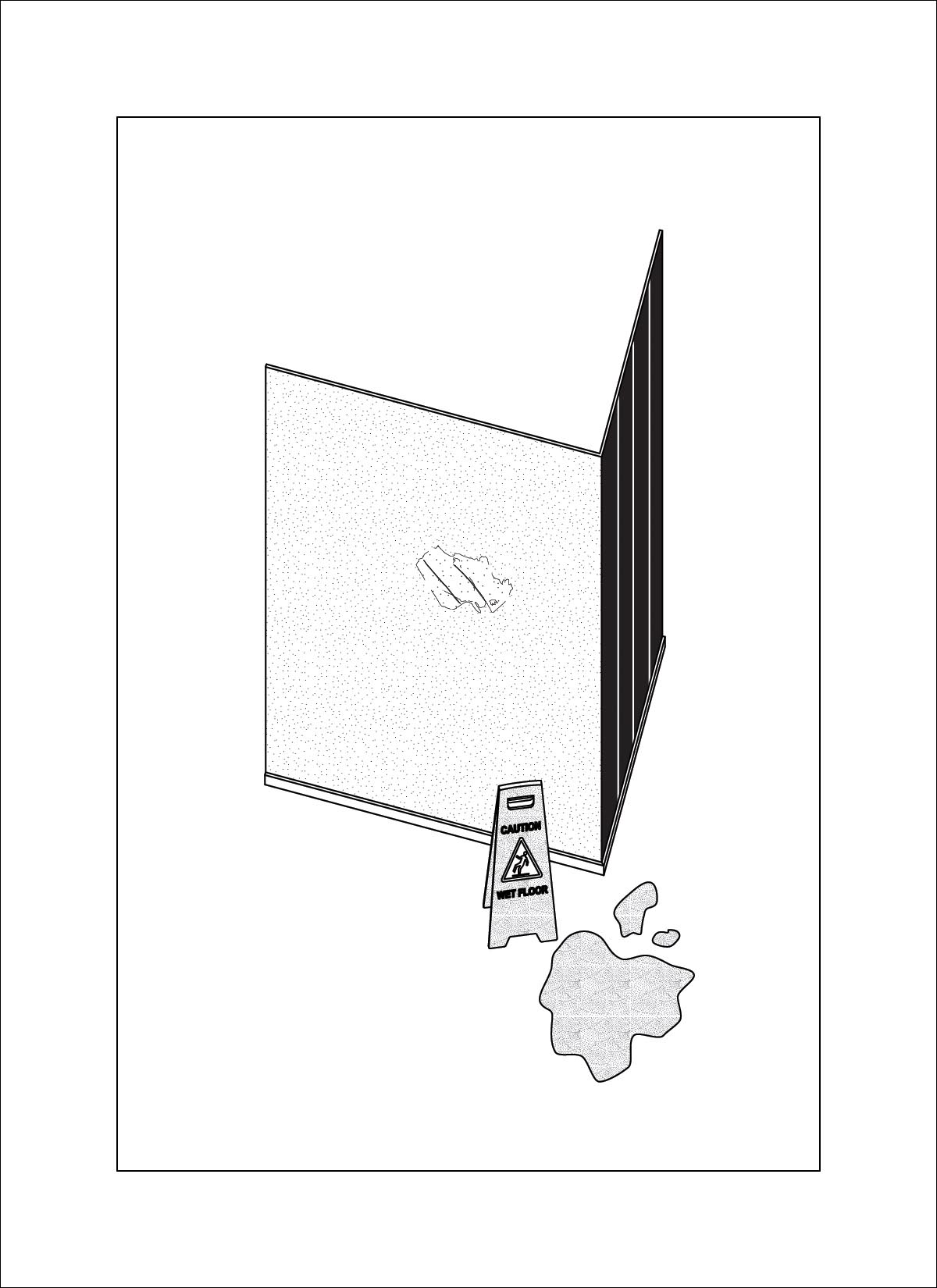
AI outputs






Note to self: use a taxonomy diagram to view all image inputs, outputs and parameters.
experiment #3
Here I’m training an AI dataset using my own thesis drawings, testing to see what kind of “new” log variations can possibly be made, and mixing it with different text/image prompts. While these are interesting generations, they are typically not feasible to fabricate.
Try this model out
dataset
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
AI outputs
![]()
![]()
![]()
![]()
![]()
![]()
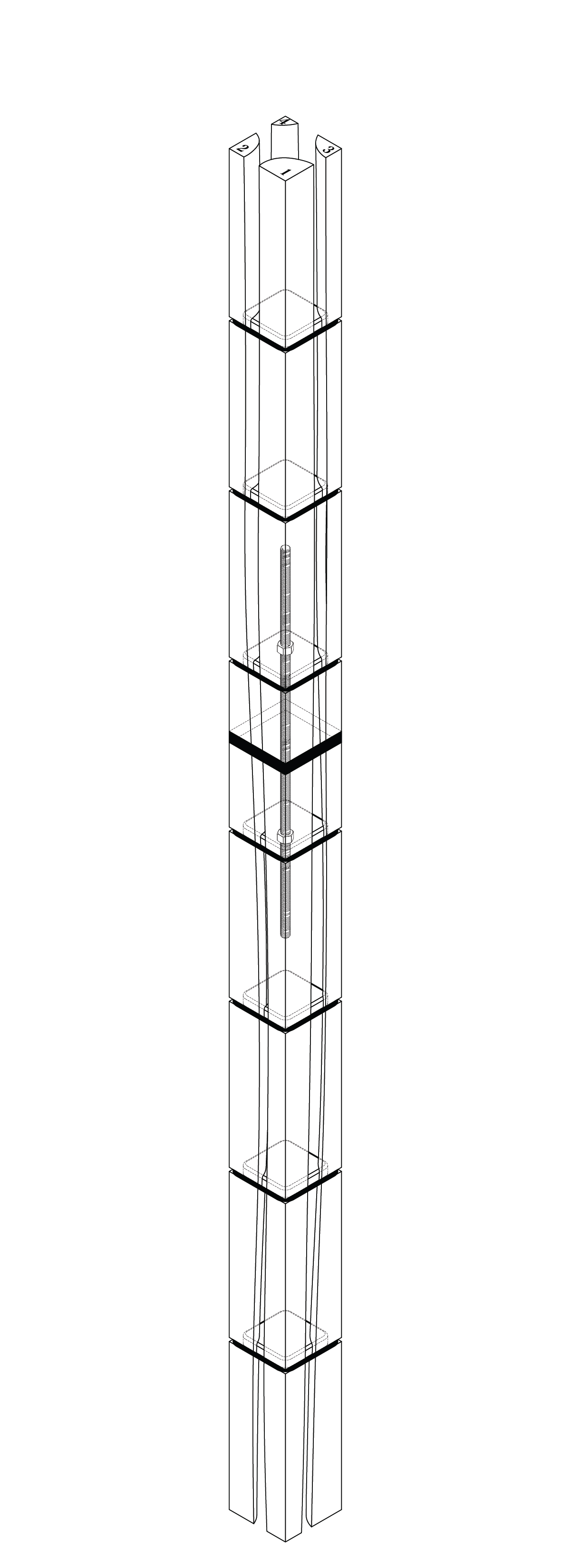
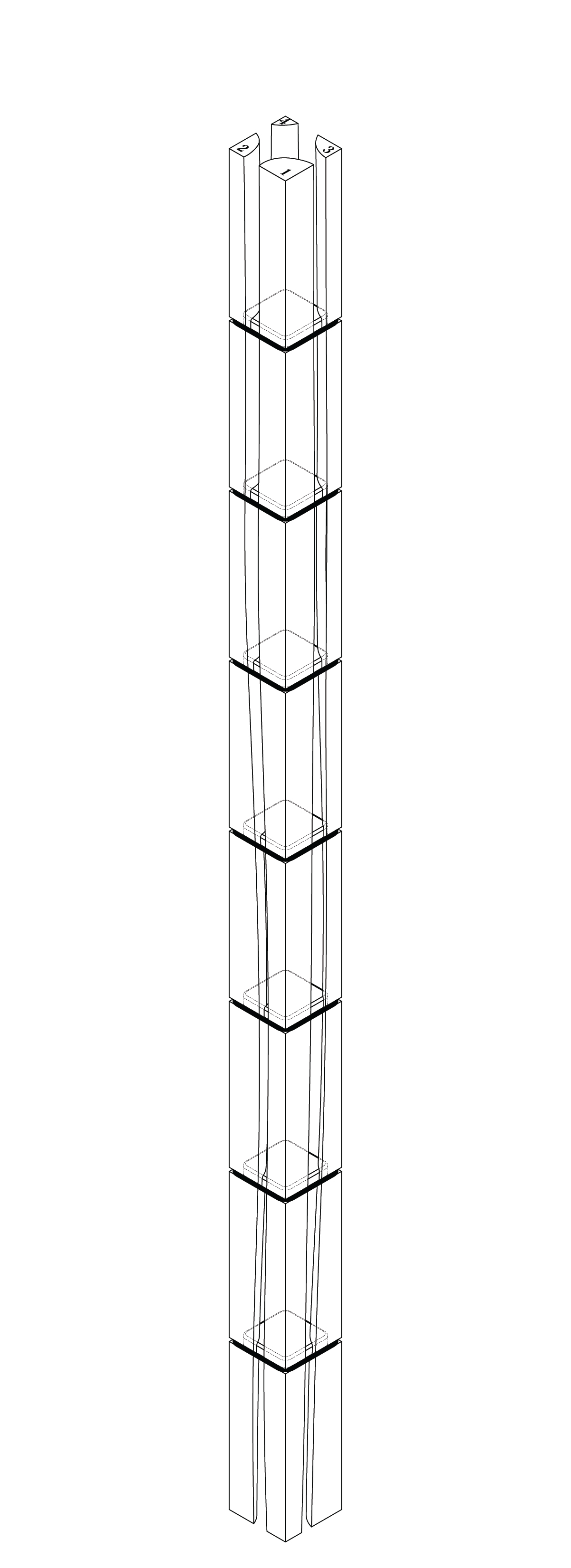
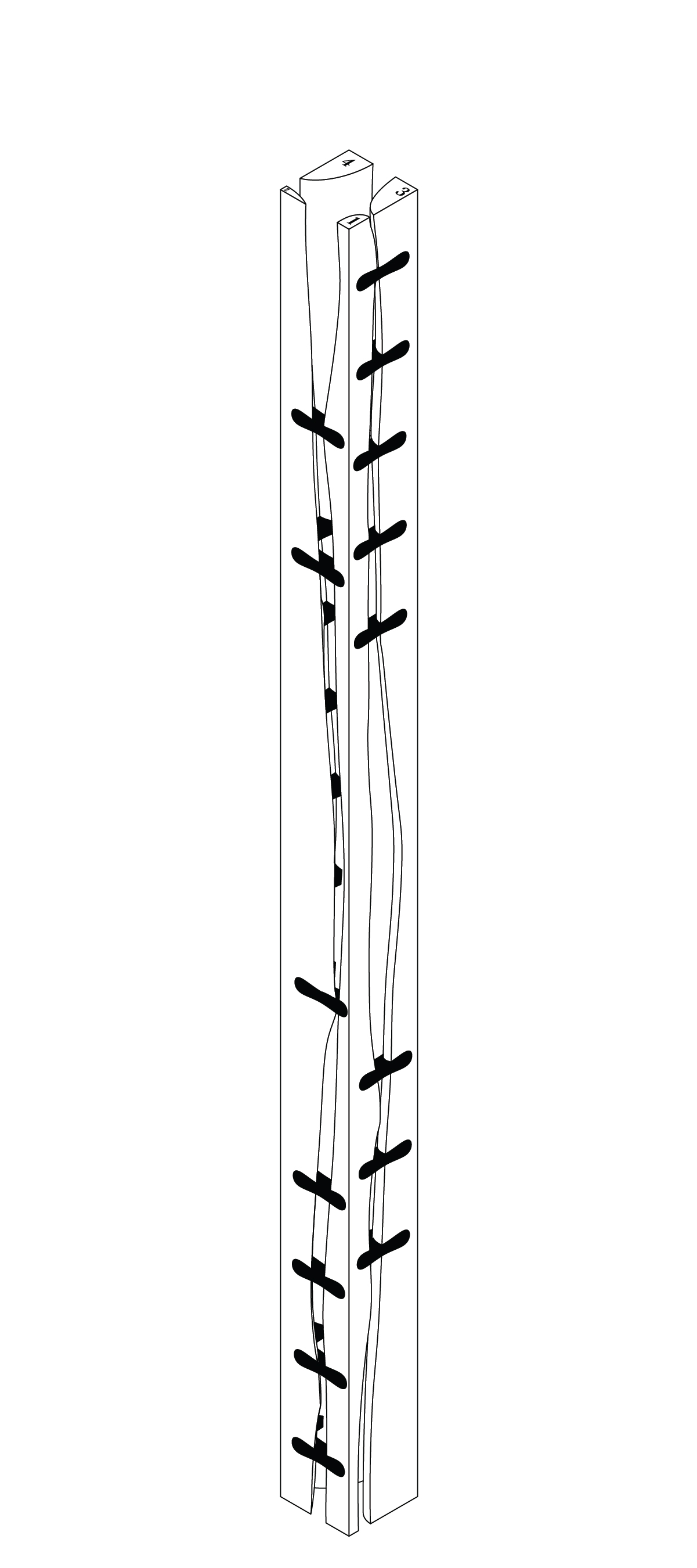


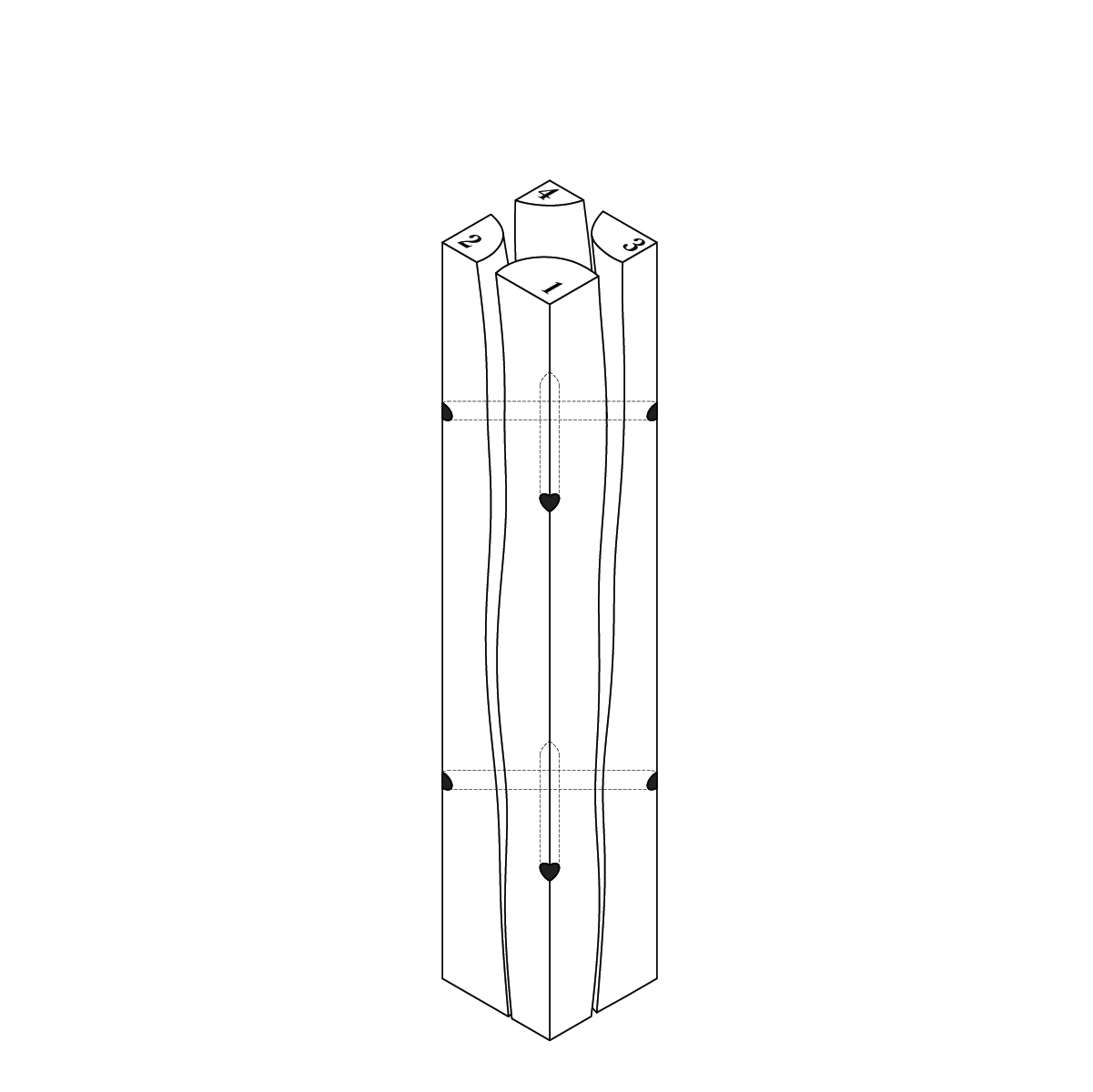
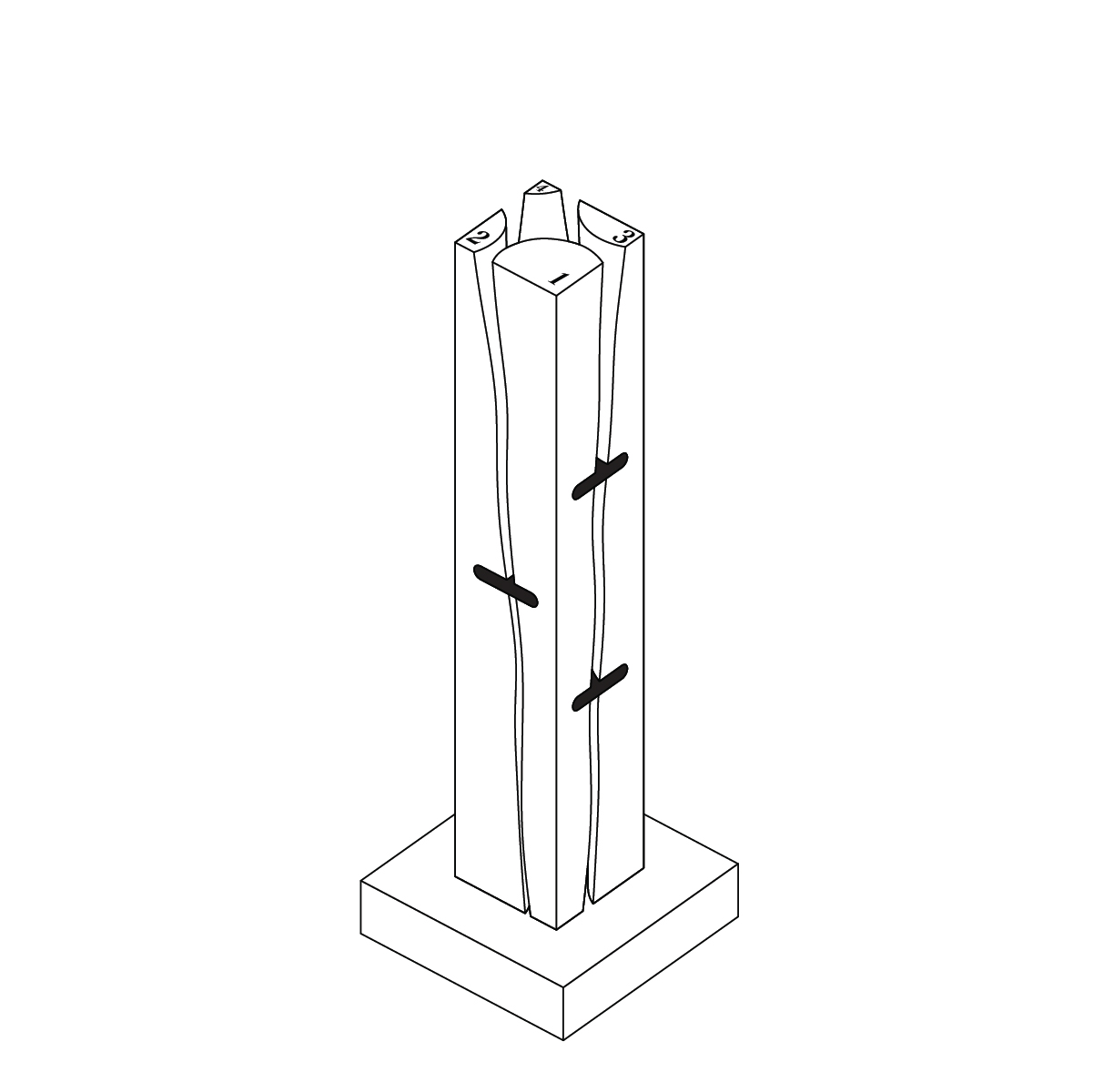

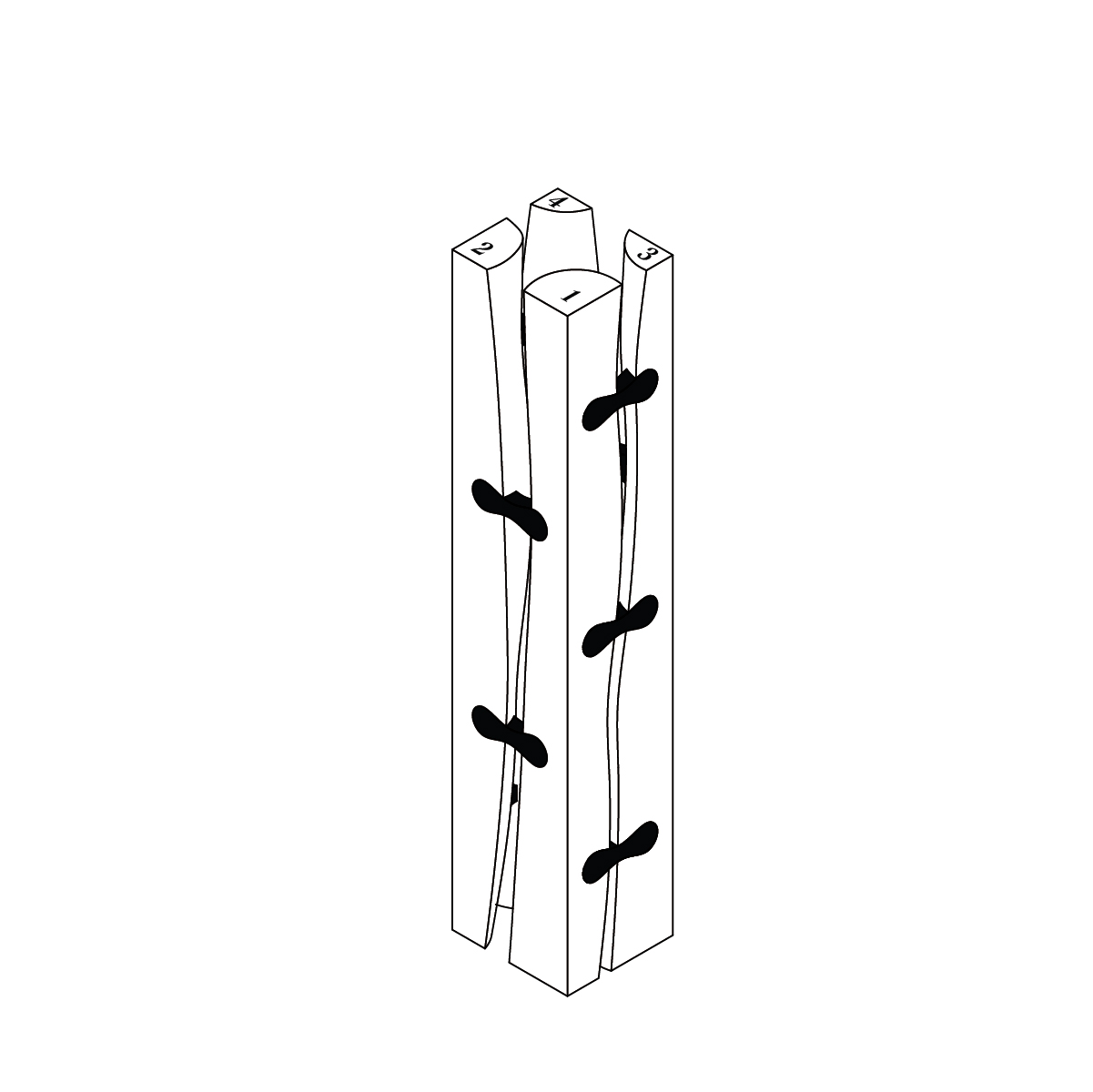

AI outputs